

The right Hadoop developers are at the heart of managing big data environments. They bridge the gap between massive data sets and actionable insights, ensuring data is accessible and usable for businesses.
Hadoop development skills encompass a deep understanding of the Hadoop ecosystem, including components like HDFS, YARN, and MapReduce, as well as programming skills in Java, Scala, or Python.
Candidates can write these abilities in their resumes, but you can’t verify them without on-the-job Hadoop Developer skill tests.
In this post, we will explore 9 essential Hadoop Developer skills, 11 secondary skills and how to assess them so you can make informed hiring decisions.
Table of contents
9 fundamental Hadoop Developer skills and traits
11 secondary Hadoop Developer skills and traits
How to assess Hadoop Developer skills and traits
Summary: The 9 key Hadoop Developer skills and how to test for them
Assess and hire the best Hadoop Developers with Adaface
Hadoop Developer skills FAQs
9 fundamental Hadoop Developer skills and traits
The best skills for Hadoop Developers include Hadoop Ecosystem, MapReduce Programming, HDFS Management, Hive and Pig, Spark, HBase, Data Ingestion Tools, YARN and Java/Scala Programming.
Let’s dive into the details by examining the 9 essential skills of a Hadoop Developer.
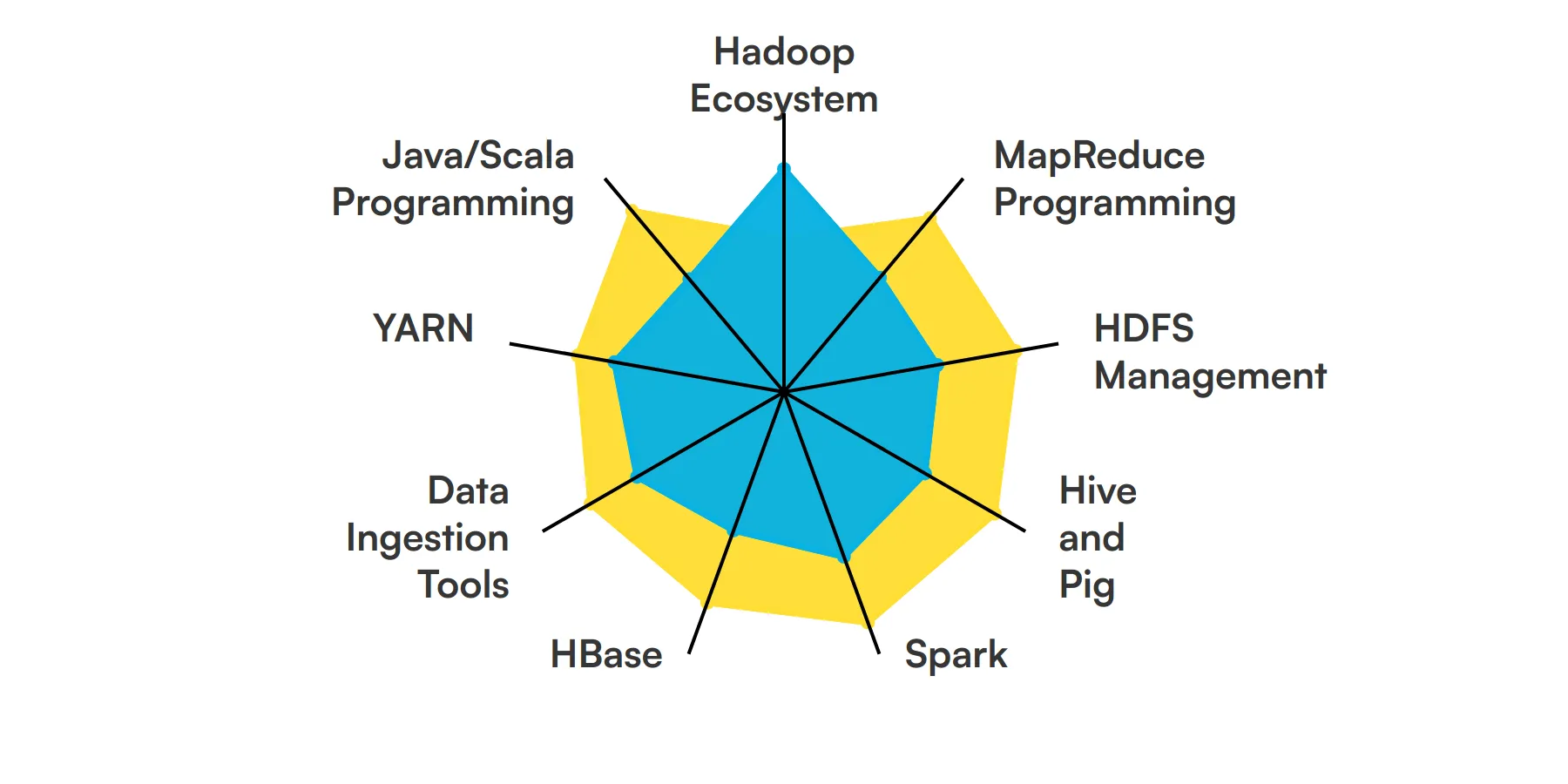
Hadoop Ecosystem
A Hadoop Developer must be well-versed in the Hadoop ecosystem, including HDFS, MapReduce, YARN, and other related tools. This knowledge is crucial for managing and processing large datasets efficiently.
For more insights, check out our guide to writing a Hadoop Developer Job Description.
MapReduce Programming
Understanding MapReduce is fundamental for a Hadoop Developer. This programming model allows for processing large data sets with a distributed algorithm on a Hadoop cluster, making it essential for data analysis tasks.
HDFS Management
Hadoop Distributed File System (HDFS) is the storage unit of Hadoop. A developer needs to know how to manage and manipulate data within HDFS, ensuring data is stored reliably and can be accessed quickly.
Hive and Pig
Hive and Pig are high-level data processing tools in the Hadoop ecosystem. Hive uses SQL-like queries, while Pig uses a scripting language. Both are essential for simplifying complex data transformations and analyses.
Check out our guide for a comprehensive list of interview questions.
Spark
Apache Spark is a powerful data processing engine that works well with Hadoop. A Hadoop Developer should know how to use Spark for faster data processing and real-time analytics.
HBase
HBase is a non-relational, distributed database that runs on top of HDFS. Knowledge of HBase is important for real-time read/write access to large datasets, which is often required in Hadoop projects.
Data Ingestion Tools
Tools like Flume and Sqoop are used for data ingestion in Hadoop. A developer must know how to use these tools to import and export data between Hadoop and other systems.
YARN
Yet Another Resource Negotiator (YARN) is the resource management layer of Hadoop. Understanding YARN is crucial for managing and scheduling resources in a Hadoop cluster.
Java/Scala Programming
Java and Scala are commonly used languages for writing Hadoop applications. Proficiency in these languages is necessary for developing efficient and scalable Hadoop solutions.
For more insights, check out our guide to writing a Scala Developer Job Description.
11 secondary Hadoop Developer skills and traits
The best skills for Hadoop Developers include Linux/Unix, Data Warehousing, ETL Processes, SQL, Machine Learning, Data Visualization, Version Control, Scripting Languages, Cloud Platforms, Data Security and Performance Tuning.
Let’s dive into the details by examining the 11 secondary skills of a Hadoop Developer.
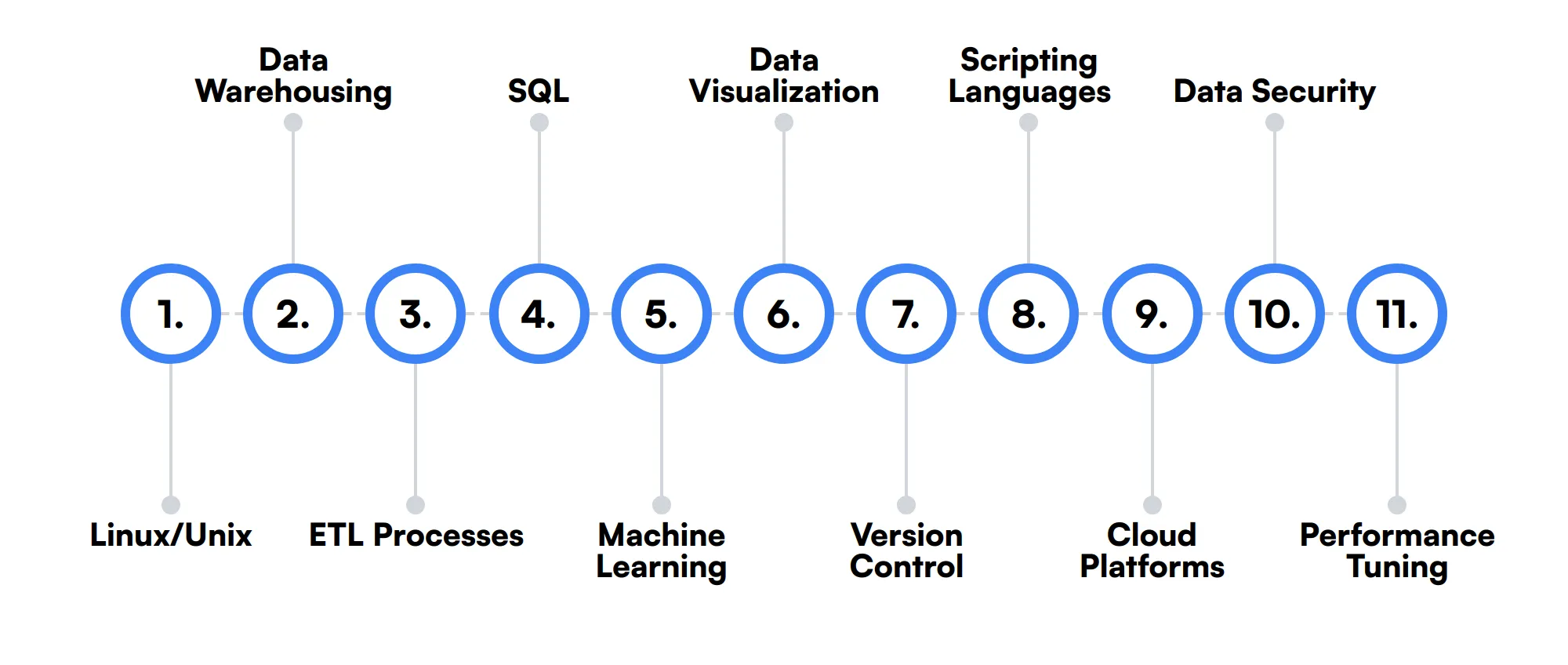
Linux/Unix
Hadoop runs on Linux/Unix systems, so familiarity with these operating systems is beneficial for managing and troubleshooting Hadoop clusters.
Data Warehousing
Understanding data warehousing concepts can help a Hadoop Developer design better data storage solutions and optimize data retrieval processes.
ETL Processes
Knowledge of Extract, Transform, Load (ETL) processes is useful for moving and transforming data within the Hadoop ecosystem.
SQL
SQL is often used in conjunction with Hadoop tools like Hive. Knowing SQL can make it easier to query and manipulate data stored in Hadoop.
Machine Learning
Familiarity with machine learning frameworks like Mahout or Spark MLlib can be advantageous for implementing advanced data analytics and predictive models.
Data Visualization
Skills in data visualization tools like Tableau or D3.js can help a Hadoop Developer present data insights in a more understandable and actionable format.
Version Control
Using version control systems like Git is important for managing code changes and collaborating with other developers on Hadoop projects.
Scripting Languages
Knowledge of scripting languages like Python or Perl can be useful for automating tasks and writing custom scripts for data processing.
Cloud Platforms
Experience with cloud platforms like AWS, Azure, or Google Cloud can be beneficial for deploying and managing Hadoop clusters in a cloud environment.
Data Security
Understanding data security practices is important for protecting sensitive data within a Hadoop ecosystem, especially in industries with strict compliance requirements.
Performance Tuning
Skills in performance tuning can help a Hadoop Developer optimize the performance of Hadoop jobs and ensure efficient use of resources.
How to assess Hadoop Developer skills and traits
Assessing the skills and traits of a Hadoop Developer can be a challenging task, given the wide range of expertise required. From understanding the Hadoop Ecosystem and MapReduce Programming to managing HDFS and working with tools like Hive, Pig, and Spark, a proficient Hadoop Developer must be well-versed in various domains.
Resumes and certifications can provide a snapshot of a candidate's background, but they don't reveal the depth of their knowledge or their ability to apply it in real-world scenarios. Skills-based assessments are the most reliable way to evaluate a candidate's true capabilities.
For instance, Adaface on-the-job skill tests can help you create customized assessments that focus on the specific skills you need, such as HBase, Data Ingestion Tools, YARN, and Java/Scala Programming. This approach not only improves the quality of hires by 2x but also reduces screening time by 85%.
Let’s look at how to assess Hadoop Developer skills with these 6 talent assessments.
Hadoop Online Test
Our Hadoop Online Test evaluates candidates on their ability to manage and analyze big data using Hadoop. The test focuses on practical skills such as installing Hadoop clusters, configuring the core Hadoop architecture, and writing efficient Hive and Pig queries.
The test assesses candidates' proficiency in handling streaming data, working with various file formats, and troubleshooting and monitoring Hadoop clusters.
Successful candidates demonstrate a strong grasp of publishing data to clusters and optimizing MapReduce jobs, essential for roles in data-intensive environments.
MapReduce Online Test
Our MapReduce Online Test challenges candidates on their knowledge of the MapReduce framework, a key component of Hadoop used for processing large data sets with a distributed algorithm.
This test evaluates a candidate's ability to design and develop applications using MapReduce, including data aggregation, transformation, and performance optimization.
Candidates proficient in MapReduce will also display strong skills in parallel computing and distributed computing, crucial for developing efficient big data processing solutions.
Hive Online Test
Our Hive Online Test assesses candidates on their expertise in Hive, focusing on areas such as Hive architecture, data modeling, and query optimization.
The test challenges candidates to demonstrate their ability to create and manage Hive databases and tables, write efficient queries, and use Hive functions effectively.
High-scoring candidates are adept at troubleshooting and optimizing Hive queries, ensuring high performance and scalability in data processing tasks.

Spark Online Test
Our Spark Online Test evaluates candidates on their ability to develop and run applications using Apache Spark, a fast and general engine for large-scale data processing.
The test covers Spark Core fundamentals, data processing with Spark SQL, and building real-time data pipelines using Spark Streaming.
Candidates excelling in this test are proficient in running Spark on clusters, implementing multi-stage algorithms, and optimizing Spark jobs, which are key skills for handling complex data processing tasks.
Sqoop Online Test
Our Sqoop Online Test assesses candidates on their ability to transfer data between Hadoop and relational databases using Sqoop, focusing on data ingestion and export commands.
This test evaluates proficiency in managing data transformation, validation, and integration processes using Sqoop-based connectors and handling both disk and network I/O efficiently.
Candidates skilled in Sqoop demonstrate strong capabilities in ETL processes and data integration, essential for roles involving large-scale data migrations and transformations.
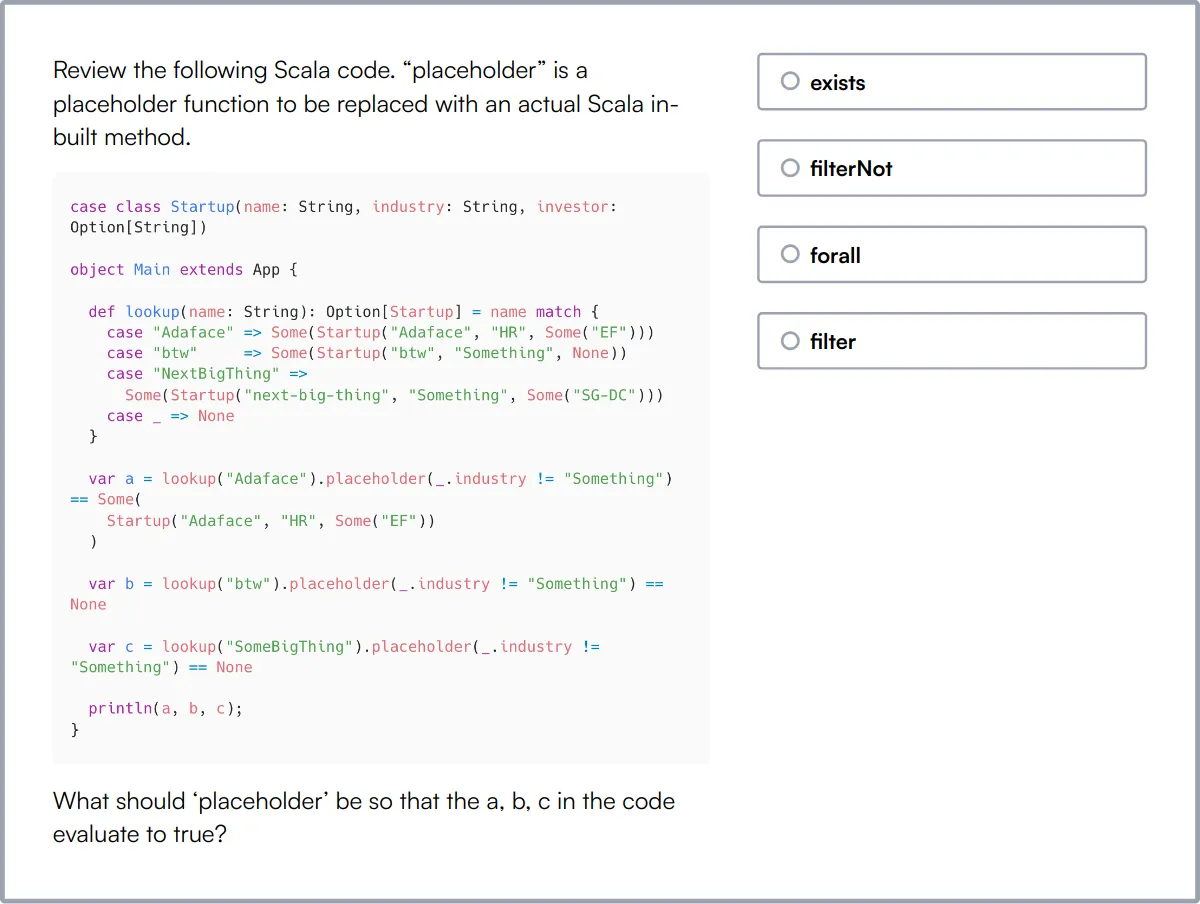
Scala Online Test
Our Scala Online Test gauges candidates' proficiency in Scala, a powerful programming language that supports both object-oriented and functional programming paradigms.
The test challenges candidates on their understanding of Scala's core features, including type inference, concurrency, and collections, as well as their ability to apply functional programming principles and handle errors effectively.
Proficient candidates will demonstrate strong problem-solving skills and the ability to develop scalable applications using Scala, reflecting their deep understanding of the language's capabilities and best practices.
Summary: The 9 key Hadoop Developer skills and how to test for them
| Hadoop Developer skill | How to assess them |
|---|---|
| 1. Hadoop Ecosystem | Evaluate understanding of various Hadoop components and their integration. |
| 2. MapReduce Programming | Assess ability to write and optimize MapReduce jobs. |
| 3. HDFS Management | Check skills in managing and maintaining Hadoop Distributed File System. |
| 4. Hive and Pig | Gauge proficiency in using Hive and Pig for data querying. |
| 5. Spark | Determine expertise in using Apache Spark for big data processing. |
| 6. HBase | Evaluate knowledge of HBase for real-time read/write access to data. |
| 7. Data Ingestion Tools | Assess experience with tools like Flume and Sqoop for data ingestion. |
| 8. YARN | Check understanding of YARN for resource management in Hadoop. |
| 9. Java/Scala Programming | Evaluate programming skills in Java or Scala for Hadoop applications. |
Hadoop Online Test
30 mins | 15 MCQs
The Hadoop Online Test uses scenario-based MCQ questions to evaluate candidates' ability to install Hadoop clusters on the cloud, run optimized MapReduce jobs on Hadoop clusters and write efficient Pig instructions and Hive queries to perform data analysis on complex datasets. The test screens for core Hadoop framework knowledge that hiring managers look for in Hadoop developers and administrators.
Try Hadoop Online Test
Hadoop Developer skills FAQs
What is the Hadoop Ecosystem and why is it important for a Hadoop Developer?
The Hadoop Ecosystem includes tools like HDFS, MapReduce, Hive, Pig, and more. Understanding these tools helps developers manage and process large datasets effectively.
How can I assess a candidate's proficiency in MapReduce Programming?
Ask candidates to explain the MapReduce process and solve a simple problem using MapReduce. Look for their understanding of key concepts like mappers, reducers, and data flow.
What skills are necessary for HDFS Management?
Candidates should know how to store, manage, and retrieve data in HDFS. Assess their ability to perform tasks like data replication, fault tolerance, and file system operations.
Why is knowledge of Hive and Pig important for a Hadoop Developer?
Hive and Pig simplify querying and analyzing large datasets. Test candidates on their ability to write HiveQL queries and Pig scripts to process data.
How do you evaluate a candidate's experience with Spark?
Ask them to describe Spark's architecture and solve a problem using Spark. Look for their understanding of RDDs, DataFrames, and Spark's execution model.
What should I look for in a candidate's experience with HBase?
Check their knowledge of HBase architecture, data modeling, and CRUD operations. Practical experience with HBase API and performance tuning is a plus.
How can I assess a candidate's skills in Data Ingestion Tools?
Evaluate their experience with tools like Flume, Sqoop, and Kafka. Ask them to describe data ingestion workflows and how they handle data from various sources.
What role does YARN play in Hadoop, and how can I test a candidate's knowledge of it?
YARN manages resources in a Hadoop cluster. Ask candidates to explain YARN's architecture and how it schedules and monitors jobs.
40 min skill tests.
No trick questions.
Accurate shortlisting.
We make it easy for you to find the best candidates in your pipeline with a 40 min skills test.
Try for freeRelated posts
Free resources

Join 1200+ companies in 80+ countries.
Try the most candidate friendly skills assessment tool today.

40 min tests.
No trick questions.
Accurate shortlisting.
No trick questions.
Accurate shortlisting.