

Data engineers are the architects of data pipelines and infrastructure. They design, build, and maintain the systems that allow organizations to collect, store, and analyze large volumes of data efficiently.
Data engineering skills include proficiency in programming languages such as Python and SQL, knowledge of data warehousing solutions, and expertise in big data technologies like Hadoop and Spark. Additionally, skills like problem-solving and attention to detail are crucial for success in this role.
Candidates can write these abilities in their resumes, but you can’t verify them without on-the-job Data Engineer skill tests.
In this post, we will explore 8 essential Data Engineer skills, 10 secondary skills and how to assess them so you can make informed hiring decisions.
Table of contents
8 fundamental Data Engineer skills and traits
10 secondary Data Engineer skills and traits
How to assess Data Engineer skills and traits
Summary: The 8 key Data Engineer skills and how to test for them
Assess and hire the best Data Engineers with Adaface
Data Engineer skills FAQs
8 fundamental Data Engineer skills and traits
The best skills for Data Engineers include SQL Expertise, Data Modeling, ETL Development, Scripting Languages, Big Data Technologies, Cloud Platforms, Data Security and Data Visualization.
Let’s dive into the details by examining the 8 essential skills of a Data Engineer.
SQL Expertise
SQL remains the cornerstone for managing and manipulating relational databases. Data engineers frequently use SQL to query and transform data, ensuring that data is accessible and usable for analytics and reporting purposes. Mastery of SQL allows data engineers to efficiently handle data retrieval and manipulation tasks.
For more insights, check out our guide to writing a SQL Developer Job Description.
Data Modeling
Understanding data modeling is crucial for data engineers as it involves structuring data in ways that ensure its quality, efficiency, and scalability. This skill helps in designing data schemas and defining how data is stored, which is fundamental for building reliable data pipelines.
ETL Development
ETL (Extract, Transform, Load) processes are at the heart of data engineering. This skill involves extracting data from various sources, transforming it to fit operational needs, and loading it into the end target database or data warehouse. Data engineers need to be adept at creating and optimizing ETL processes to support data transformation and integration tasks.
Check out our guide for a comprehensive list of interview questions.
Scripting Languages
Proficiency in scripting languages such as Python or Bash is essential for automating repetitive data processing tasks. Data engineers use these skills to write scripts that aid in data manipulation, pipeline construction, and automation of data workflows.
Big Data Technologies
Familiarity with big data technologies like Hadoop, Spark, and Kafka is necessary for handling large-scale data processing. Data engineers use these tools to efficiently process, store, and analyze vast amounts of data in real time.
For more insights, check out our guide to writing a Big Data Engineer Job Description.
Cloud Platforms
Knowledge of cloud services (AWS, Azure, Google Cloud) is important as many data storage and processing tasks are now cloud-based. Data engineers use these platforms to deploy scalable and flexible data pipelines and infrastructure.
Data Security
Ensuring the security and compliance of data systems is a key responsibility of data engineers. They must be knowledgeable about data encryption, secure data transfer, and compliance regulations to protect sensitive information and maintain trust.
Check out our guide for a comprehensive list of interview questions.
Data Visualization
While not always front and center, the ability to visualize data effectively helps data engineers to communicate findings and validate the results of data transformations. Tools like Tableau or PowerBI are often used to create impactful visual representations of data.
10 secondary Data Engineer skills and traits
The best skills for Data Engineers include Version Control, Machine Learning, Database Tuning, API Integration, Containerization, Real-time Processing, Data Governance, NoSQL Databases, Data Quality Management and Project Management.
Let’s dive into the details by examining the 10 secondary skills of a Data Engineer.
Version Control
Using version control systems like Git helps data engineers manage changes to their codebase, collaborate with others, and maintain a history of project evolution.
Machine Learning
A working knowledge of machine learning principles can be beneficial for data engineers to support advanced analytics projects and to implement predictive models directly within data pipelines.
Database Tuning
Skills in database performance tuning are important to optimize the speed and efficiency of database systems, which directly impacts the performance of data applications.
API Integration
Data engineers often need to integrate with various APIs to pull data from different services. Understanding API integration techniques is useful for expanding data collection and automation capabilities.
Containerization
Knowledge of container technologies like Docker and Kubernetes is valuable for deploying applications and data pipelines in a consistent, scalable, and isolated environment.
Real-time Processing
Skills in real-time data processing are important for projects that require immediate insights from streaming data, using tools like Apache Storm or Flink.
Data Governance
Understanding data governance frameworks is beneficial for managing the availability, usability, integrity, and security of the data in enterprise systems.
NoSQL Databases
Familiarity with NoSQL databases like MongoDB, Cassandra, or Redis is useful for projects that require flexible schema and scalability for large volumes of data.
Data Quality Management
Ensuring data quality is critical for reliable analytics. Data engineers need to implement processes and tools to monitor, clean, and ensure the accuracy of data.
Project Management
While technical, having project management skills helps data engineers to plan, execute, and deliver data projects within scope and time constraints.
How to assess Data Engineer skills and traits
Assessing the skills and traits of a Data Engineer can be a challenging task. Data Engineers require a unique blend of technical expertise and problem-solving abilities to manage and optimize data pipelines effectively. While resumes and certifications provide a snapshot of a candidate's background, they often fall short in revealing the true depth of their skills and how well they can apply them in real-world scenarios.
To truly understand a candidate's proficiency in key areas such as SQL expertise, data modeling, ETL development, scripting languages, big data technologies, cloud platforms, data security, and data visualization, skills-based assessments are indispensable. These assessments allow you to evaluate a candidate's practical abilities and ensure they are a good fit for your specific needs.
One effective way to streamline this process is by using Adaface on-the-job skill tests. These tests can help you achieve a 2x improved quality of hires and an 85% reduction in screening time. By focusing on real-world tasks and scenarios, Adaface assessments provide a comprehensive evaluation of a candidate's capabilities, ensuring you make informed hiring decisions.
Let’s look at how to assess Data Engineer skills with these 6 talent assessments.
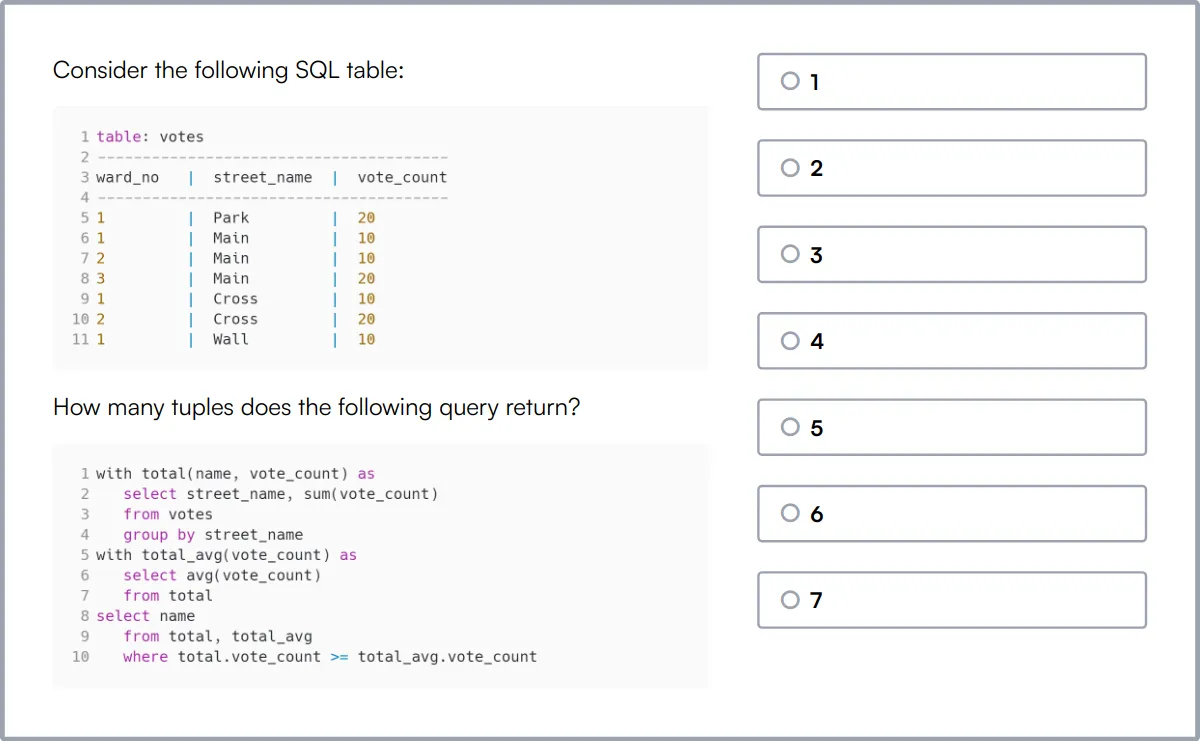
SQL Online Test
Our SQL Online Test evaluates a candidate's ability to design and build relational databases, manage tables, and write efficient SQL queries including joins and subqueries.
The test assesses skills in database operations such as CRUD, handling transactions, and implementing security measures in SQL environments.
Candidates who perform well demonstrate a strong grasp of SQL syntax, query optimization, and database schema design.
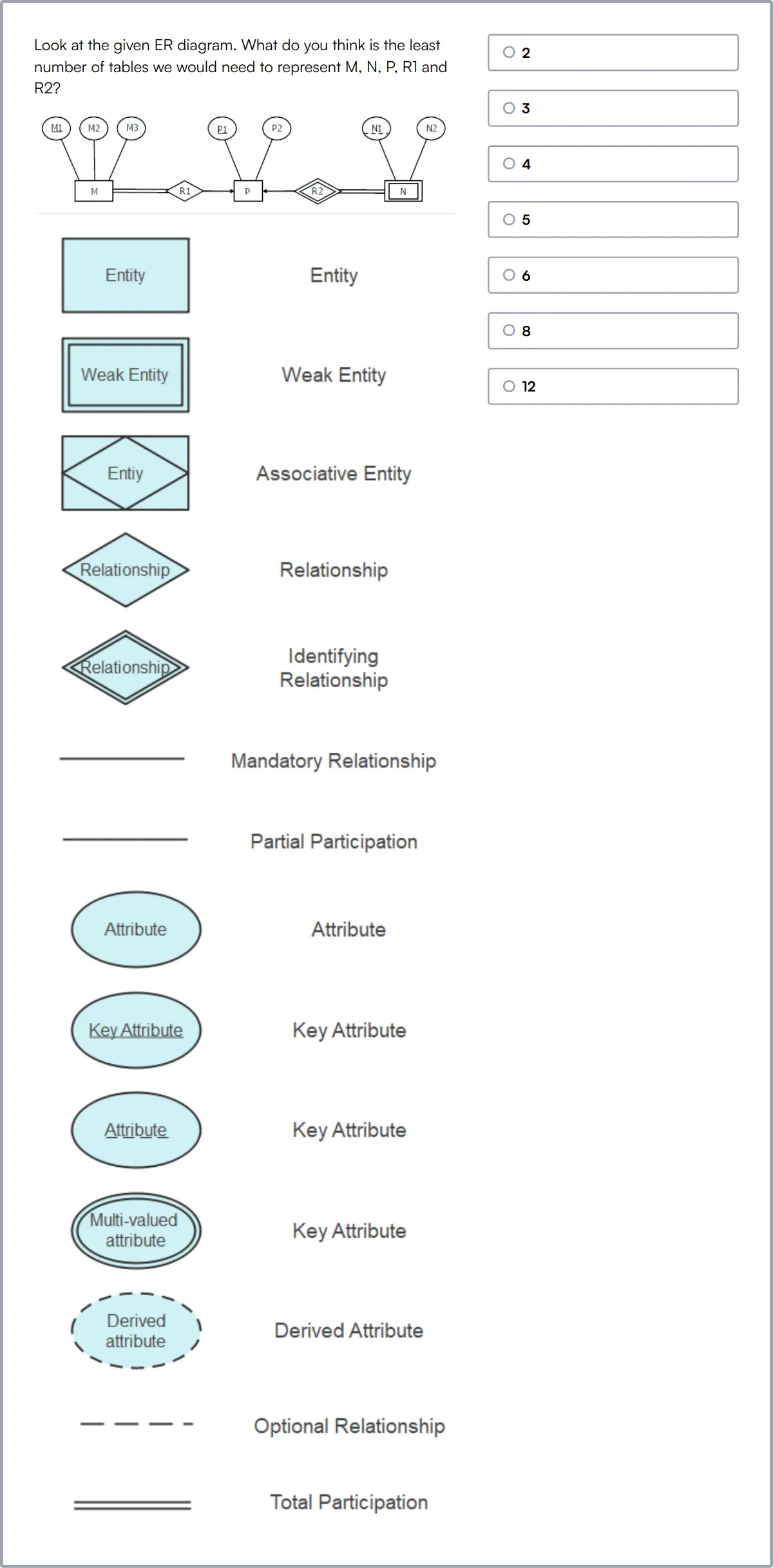
Data Modeling Skills Test
The Data Modeling Skills Test measures a candidate's proficiency in designing databases and implementing data structures using SQL, ER diagrams, and normalization techniques.
This test evaluates the candidate's ability to ensure data integrity, perform data mapping, and execute data transformations effectively.
High-scoring individuals show adeptness in creating accurate relational schemas and managing complex data modeling scenarios.
Informatica Online Test
Our Informatica Online Test assesses a candidate's skills in using Informatica PowerCenter for ETL processes, data integration, and data warehousing.
The test challenges candidates with scenarios involving data synchronization, replication tasks, and designing data transformations without writing SQL.
Successful candidates will demonstrate proficiency in managing workflows, sessions, and tasks within Informatica environments.
Python Online Test
The Python Online Test evaluates a candidate's command over Python programming, including data structures, OOP, and error handling.
It tests the ability to script effectively, manipulate data using Python's in-built functions, and integrate with databases.
Candidates excelling in this test are adept at writing clean, maintainable code and debugging complex Python applications.
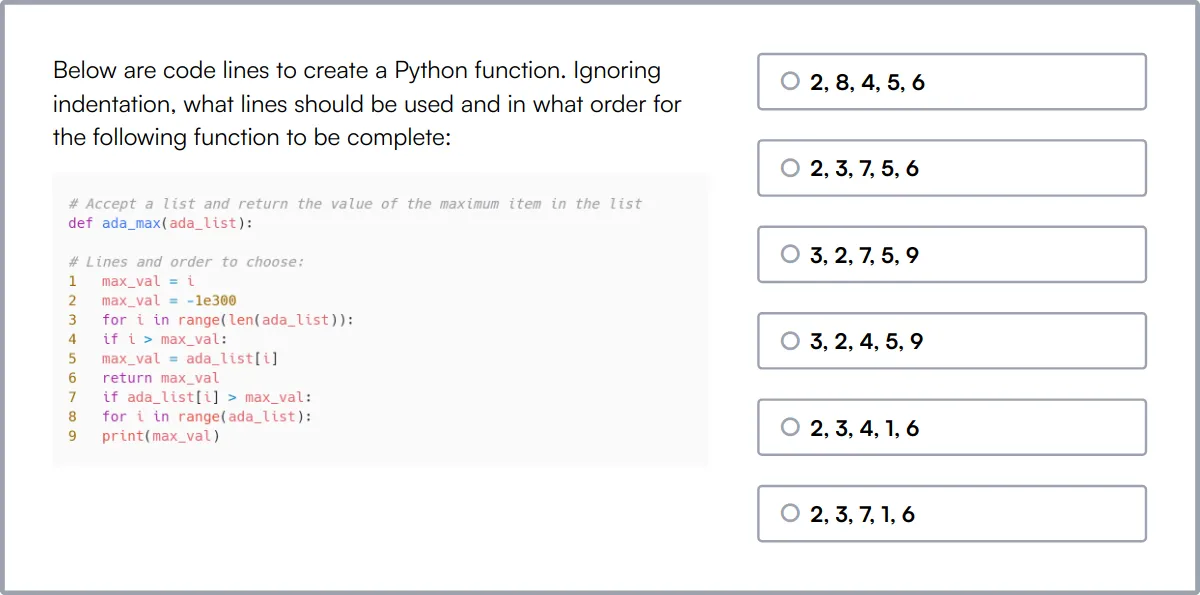
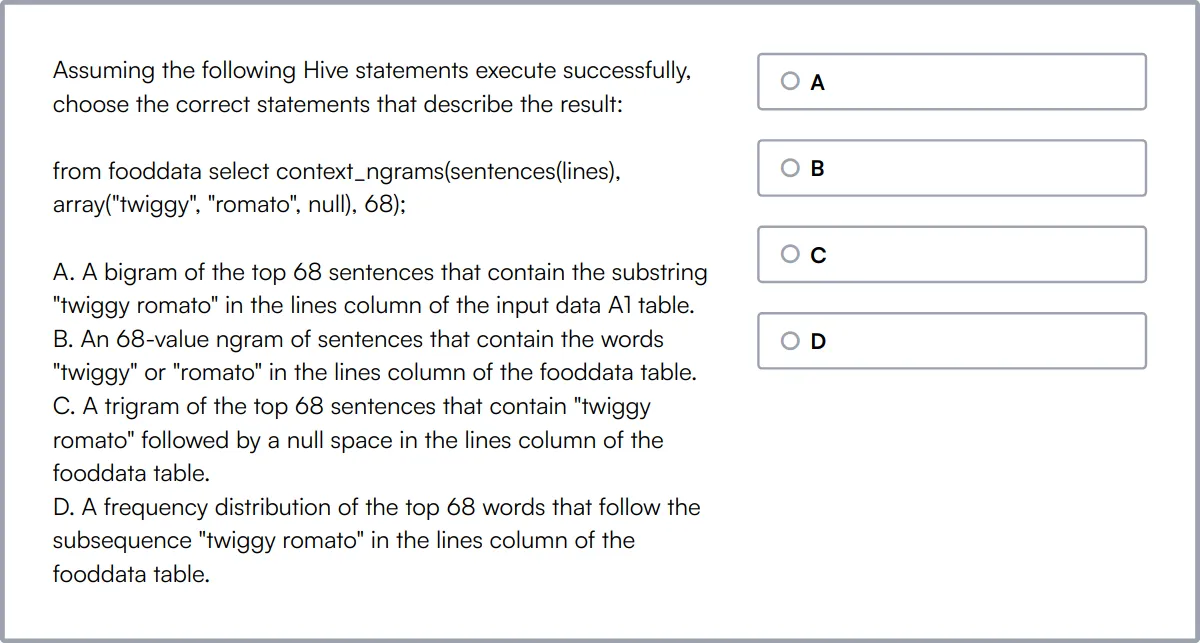
Hadoop Online Test
Our Hadoop Online Test gauges a candidate's ability to manage Hadoop clusters, and process data using Hive and Pig within the Hadoop ecosystem.
The test evaluates skills in configuring Hadoop environments, optimizing MapReduce jobs, and handling large-scale data across distributed systems.
Top performers are skilled in troubleshooting and monitoring Hadoop clusters to ensure efficient data processing and storage.
Advance Networking in AWS Online Test
The Advance Networking in AWS Online Test assesses a candidate's understanding of AWS networking features like VPC, subnets, and route tables.
This test challenges candidates to design, configure, and troubleshoot network architectures using AWS services effectively.
Candidates who score well are proficient in implementing secure and scalable network infrastructures within AWS.
Summary: The 8 key Data Engineer skills and how to test for them
| Data Engineer skill | How to assess them |
|---|---|
| 1. SQL Expertise | Evaluate ability to write and optimize complex queries. |
| 2. Data Modeling | Assess skills in designing efficient and scalable data structures. |
| 3. ETL Development | Check proficiency in building and managing ETL pipelines. |
| 4. Scripting Languages | Gauge capability in automating tasks using languages like Python or Bash. |
| 5. Big Data Technologies | Determine experience with tools like Hadoop, Spark, or Kafka. |
| 6. Cloud Platforms | Evaluate familiarity with AWS, Azure, or Google Cloud services. |
| 7. Data Security | Assess knowledge in implementing data protection and compliance measures. |
| 8. Data Visualization | Check ability to create insightful visual representations of data. |
Data Analytics in AWS Online Test
30 mins | 15 MCQs
The Data Analytics in AWS test evaluates a candidate's knowledge in data analytics and AWS services. It includes multiple choice questions to assess their understanding of data analytics concepts and ability to use AWS services for data analysis.
Try Data Analytics in AWS Online Test
Data Engineer skills FAQs
What SQL skills should a Data Engineer have?
A Data Engineer should be proficient in writing complex queries, optimizing SQL performance, and understanding database schemas. Knowledge of different SQL databases like MySQL, PostgreSQL, and SQL Server is also important.
How can I assess a candidate's data modeling skills?
Ask candidates to design a data model for a given business scenario. Evaluate their understanding of normalization, relationships, and indexing. Practical tests or case studies can be very effective.
What are the key aspects of ETL development to evaluate?
Assess their experience with ETL tools like Apache NiFi, Talend, or Informatica. Check their ability to design, implement, and optimize ETL pipelines, and handle data transformations and migrations.
Which scripting languages are important for Data Engineers?
Python and SQL are the most commonly used scripting languages. Knowledge of Bash, Perl, or JavaScript can also be beneficial for automating tasks and data manipulation.
What should I look for in a candidate's experience with Big Data technologies?
Look for experience with Hadoop, Spark, and Kafka. Assess their ability to handle large datasets, perform distributed computing, and use tools like Hive and Pig.
How can I evaluate a candidate's proficiency with cloud platforms?
Check their experience with AWS, Google Cloud, or Azure. Ask about specific services like S3, Redshift, BigQuery, or Dataflow. Practical tests on cloud-based data tasks can be insightful.
What are the important aspects of data security for a Data Engineer?
Evaluate their understanding of data encryption, access controls, and compliance standards like GDPR. Ask about their experience with securing data pipelines and databases.
How can I assess a candidate's skills in data visualization?
Look for experience with tools like Tableau, Power BI, or Looker. Ask them to create visualizations from a dataset and explain their choices. Assess their ability to convey insights effectively.
40 min skill tests.
No trick questions.
Accurate shortlisting.
We make it easy for you to find the best candidates in your pipeline with a 40 min skills test.
Try for freeRelated posts
Free resources

Join 1200+ companies in 80+ countries.
Try the most candidate friendly skills assessment tool today.

40 min tests.
No trick questions.
Accurate shortlisting.
No trick questions.
Accurate shortlisting.