

Data engineers are the architects of an organization's data infrastructure, bridging the gap between raw data and actionable insights. Many companies struggle to find the right talent because they underestimate the complexity of the role or fail to assess candidates' technical skills accurately. A successful data engineer hire can transform your data strategy, while a poor fit can lead to costly setbacks and inefficiencies.
This comprehensive guide will walk you through the process of hiring a top-notch data engineer, from understanding the role to conducting effective interviews. We'll cover key skills, qualifications, and practical tips to help you attract and identify the best candidates. For a deeper dive into specific skills, check out our detailed guide on skills required for data engineers.
Table of contents
What Does a Data Engineer Do?
Data Engineer Hiring Process
Key Skills and Qualifications for Hiring a Data Engineer
How to Write an Effective Data Engineer Job Description
Top Platforms to Find and Hire Data Engineers
Keywords to Look for in a Data Engineer Resume
Recommended Skills Tests to Screen Data Engineers
Case Study Assignments to Hire Data Engineers
Structuring Technical Interviews for Data Engineer Candidates
How much does it cost to hire a Data Engineer?
What's the difference between a Data Engineer and a Big Data Engineer?
What are the ranks of Data Engineers?
Hire the Best Data Engineers for Your Team
What Does a Data Engineer Do?
A data engineer is responsible for designing, building, and maintaining the data infrastructure that supports an organization's analytics and data science initiatives. They create robust systems to collect, store, and process large volumes of data from various sources, ensuring it's accessible and usable for analysis.
The day-to-day tasks of a data engineer include:
- Developing and managing data pipelines
- Implementing data warehouses and data lakes
- Optimizing database performance
- Ensuring data quality and security
- Collaborating with data scientists and analysts
- Creating and maintaining ETL (Extract, Transform, Load) processes
- Integrating new data sources into existing systems
Data Engineer Hiring Process
The Data Engineer hiring process typically takes around 1-2 months. Here's a quick overview:
- Craft a detailed job description and post it on relevant job boards.
- Review resumes as they come in (expect a good flow within the first week).
- Shortlist candidates and conduct technical assessments to evaluate their skills (around 1 week).
- Conduct interviews with the top candidates (1-2 weeks).
- Make an offer to the best candidate.
Overall, the process can take 1-2 months, depending on the urgency and the quality of the candidate pool. Let's dive into each step in more detail.
Key Skills and Qualifications for Hiring a Data Engineer
When hiring a Data Engineer, it's important to build a well-defined candidate profile. Many recruiters overlook the nuanced skills required for this role, leading to mismatched expectations. Distinguishing between required and preferred skills can streamline your hiring process and attract the right talent.
The required skills typically include a Bachelor's degree in Computer Science or a related field, proficiency in programming languages such as Python or Java, and strong experience with SQL. Additionally, familiarity with big data tools like Hadoop and an understanding of data warehousing solutions like Redshift are essential.
On the other hand, preferred skills may include a Master's degree, experience with cloud platforms like AWS, and familiarity with ETL tools such as Informatica. While not necessary, these qualifications can help differentiate candidates and lead to a stronger team dynamic.
| Required skills and qualifications | Preferred skills and qualifications |
|---|---|
| Bachelor's degree in Computer Science, Engineering, or a related field | Master's degree in a relevant field |
| Proficiency in programming languages such as Python, Java, or Scala | Experience with cloud platforms such as AWS, Azure, or Google Cloud |
| Strong experience with SQL and database management systems | Familiarity with ETL tools like Informatica or Talend |
| Experience with big data tools like Hadoop, Spark, or Kafka | Experience with version control systems such as Git |
| Understanding of data warehousing solutions such as Redshift or Snowflake | Proven success in a collaborative, team-oriented environment |
How to Write an Effective Data Engineer Job Description
Once you've defined the ideal candidate profile, the next step is crafting a compelling job description to attract top-tier data engineering talent. Here are some key tips to make your Data Engineer job description stand out:
- Highlight key responsibilities and impact: Clearly outline the role's core duties, expected outcomes, and how the data engineer's work will drive organizational success.
- Balance technical requirements with soft skills: List specific technical skills like proficiency in SQL, Python, and big data technologies, but also emphasize soft skills such as problem-solving and teamwork.
- Showcase your company's unique selling points: Highlight exciting projects, growth opportunities, or innovative technologies that set your role apart from competitors.
- Be clear about experience level: Specify whether you're seeking entry-level, mid-level, or senior data engineers to attract candidates with the right experience.
Top Platforms to Find and Hire Data Engineers
Now that you have a well-crafted job description, it's time to post it on job listing sites to attract qualified candidates. The right platform can make a big difference in finding the best Data Engineers for your team. Let's explore some top options for sourcing these tech professionals.
LinkedIn Jobs
Ideal for posting full-time positions and reaching a large pool of professional Data Engineers. Offers robust search and filtering options for recruiters.
Indeed
Versatile platform suitable for posting various job types including full-time, part-time, and contract positions. Reaches a wide audience of job seekers.
Dice
Specialized job board for tech roles, including Data Engineers. Ideal for reaching candidates with specific technical skills and experience.
Beyond these major players, there are several other platforms worth considering. Some cater to freelancers, while others focus on startups or remote work. Each has its strengths, so choose based on your specific needs and the type of Data Engineer you're looking to hire. Remember to use skills assessment tools to evaluate candidates effectively once you start receiving applications.
Keywords to Look for in a Data Engineer Resume
Resume screening is a time-saving step in the hiring process. It helps you quickly identify candidates who match your requirements before moving to interviews.
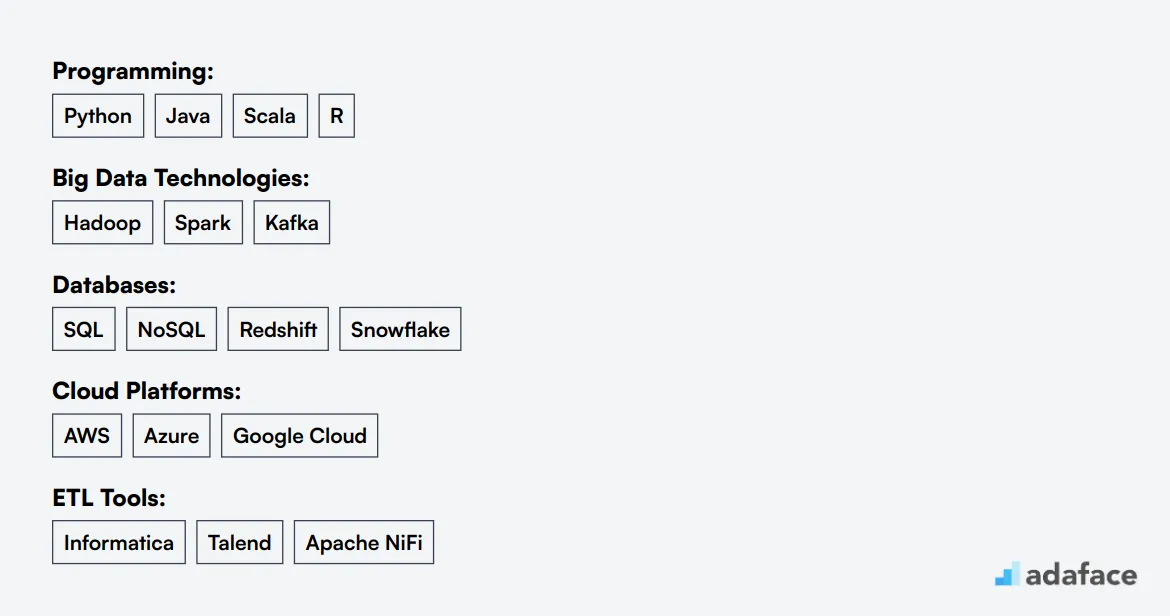
When manually screening resumes, focus on key technical skills and experiences. Look for programming languages like Python and Java, database expertise (SQL), and experience with big data tools such as Hadoop or Spark. These align with the core skills required for data engineers.
AI-powered tools can streamline resume screening. You can use large language models like ChatGPT or Claude by providing them with a prompt that includes your job requirements and desired keywords. This approach can help you process large volumes of resumes quickly.
TASK: Screen resumes for Data Engineer role
INPUT: Resumes
OUTPUT:
- Candidate Name
- Matching keywords
- Score (out of 10)
- Shortlist recommendation (Yes/No/Maybe)
KEYWORDS:
- Programming: Python, Java, Scala
- Databases: SQL, NoSQL
- Big Data: Hadoop, Spark, Kafka
- Cloud: AWS, Azure, Google Cloud
- ETL: Informatica, Talend
- Data Warehousing: Redshift, Snowflake
Recommended Skills Tests to Screen Data Engineers
To hire the right data engineers, it's important to use skills tests that accurately measure their technical abilities. Skills testing helps ensure that candidates possess the necessary expertise before moving forward in the hiring process.
Data Engineer Test: This test evaluates candidates on their core competencies in data engineering, including data pipeline creation and management. It's designed to identify candidates who can handle large volumes of data across various platforms.
SQL Online Test: SQL is a fundamental part of data engineering, used for querying and manipulating databases. This test assesses candidates' proficiency in writing complex queries and optimizing database performance.
Python Online Test: Python is widely used in data engineering for automation and data processing. The Python test checks candidates' ability to write clean, efficient code and their grasp of essential libraries and frameworks.
Hadoop Online Test: Hadoop is crucial for working with large data sets. This test measures the candidate's understanding of the Hadoop ecosystem and their ability to implement it in real-world scenarios.
Spark Online Test: Apache Spark enables real-time data processing. This test evaluates the candidate's skills in leveraging Spark for data transformation and analysis, ensuring they can handle fast data processing needs.
Case Study Assignments to Hire Data Engineers
Case study assignments can be a valuable tool in hiring Data Engineers, but they come with their own set of challenges. While they allow you to assess candidates' practical skills and problem-solving abilities, they can also be lengthy and deter potential candidates, resulting in lower test-taking rates. It's important to carefully choose assignments that are engaging and reflective of real job scenarios.
Data Pipeline Design: This case study involves evaluating a candidate's ability to design a scalable and reliable data pipeline. It's a great way to assess how a candidate thinks about data flow, error handling, and technology choices. Designing a data pipeline is a core skill for data engineers, allowing you to gauge their fit for your projects.
ETL Process Implementation: Here, candidates are tasked with designing and implementing an ETL (Extract, Transform, Load) process. This assignment helps in understanding their grasp of data transformation and database interaction. You can view sample ETL testing interview questions to get an idea of what to look for.
Data Warehouse Optimization: This involves tasks related to optimizing a data warehouse for performance and cost. It is essential for assessing a candidate's ability to work with large datasets and optimize systems for speed and efficiency. This assignment highlights their problem-solving skills in a practical context.
Structuring Technical Interviews for Data Engineer Candidates
After candidates pass the initial skills tests, it's time for technical interviews to assess their hard skills in depth. While skills tests are great for filtering out unqualified applicants, technical interviews help identify the best fit for the role. Let's look at some sample interview questions to evaluate Data Engineer candidates effectively.
Consider asking: 1) 'Explain the ETL process and its importance in data engineering.' 2) 'How would you design a data pipeline for real-time streaming data?' 3) 'What's your experience with cloud platforms like AWS or Azure?' 4) 'Can you describe a challenging data integration project you've worked on?' 5) 'How do you ensure data quality and integrity in your work?' These questions help assess the candidate's technical knowledge, problem-solving skills, and real-world experience in data engineering tasks.
How much does it cost to hire a Data Engineer?
The cost of hiring a Data Engineer varies widely based on location and experience. In the United States, the average salary for Data Engineers is around $133,000, with a range from $82,000 to $192,000. Other countries like Australia and Canada also offer competitive salaries, with averages around $130,000 AUD and $106,000 CAD respectively.
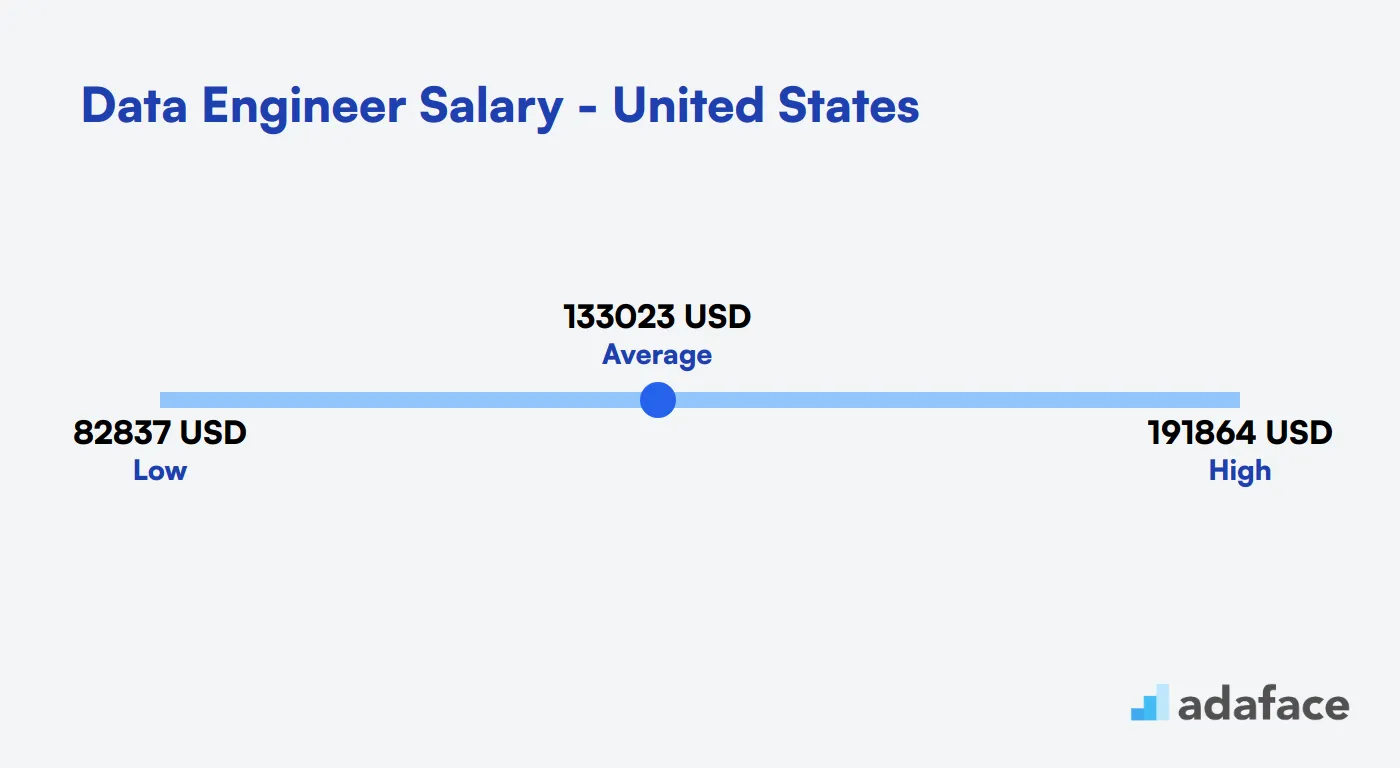
Data Engineer Salary in the United States
The average salary for Data Engineers in the United States is $133,024. Salaries typically range from $82,838 to $191,864, depending on factors like location, experience, and company size.
Top-paying cities for Data Engineers include San Jose and San Francisco, with median salaries of $172,441 and $160,804 respectively. Other high-paying locations are Jersey City, Jacksonville, and Redmond, offering competitive compensation packages.
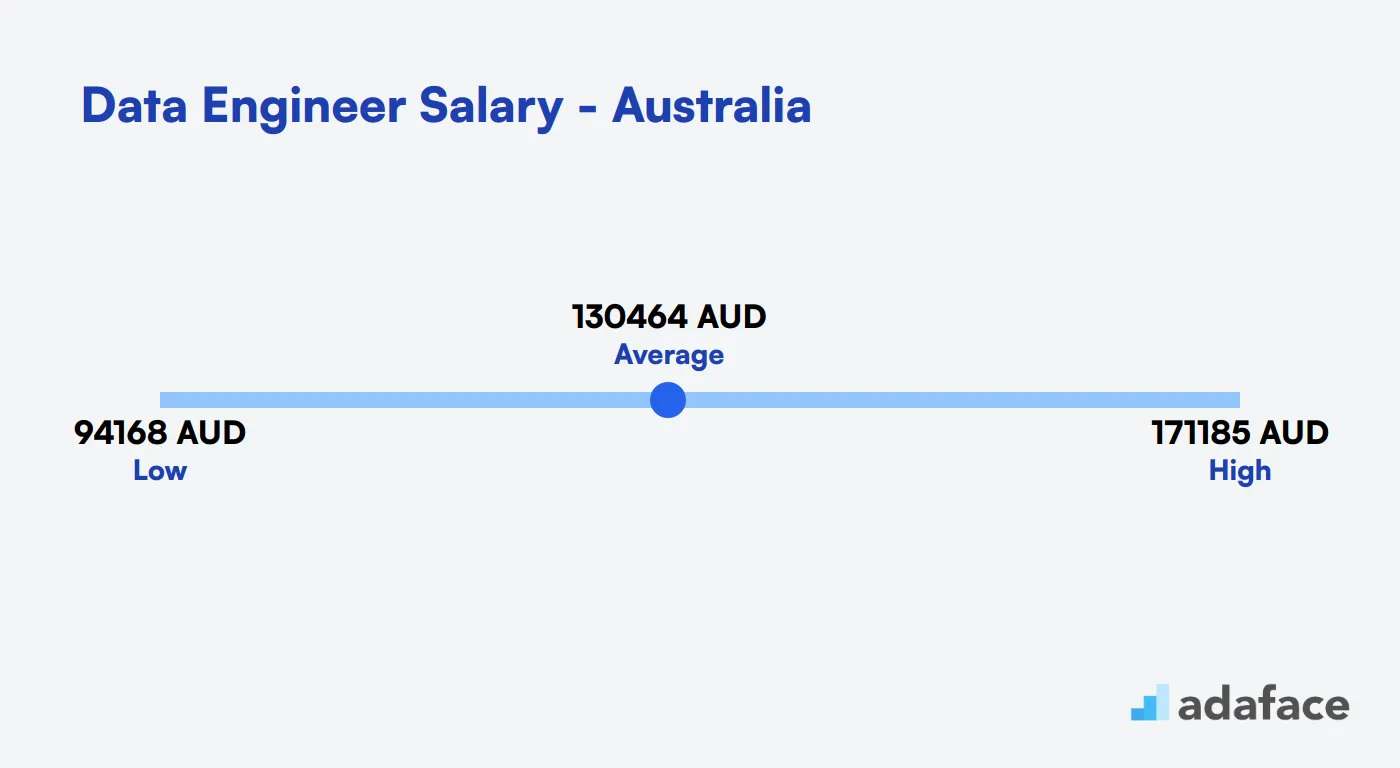
Data Engineer Salary in Australia
In Australia, Data Engineers earn an average salary of approximately $130,465 AUD. Salaries vary significantly by location; for instance, in Canberra, the average can reach $252,434 AUD, while in Adelaide, it drops to about $106,261 AUD. Understanding these figures can help you set competitive offers to attract qualified candidates.
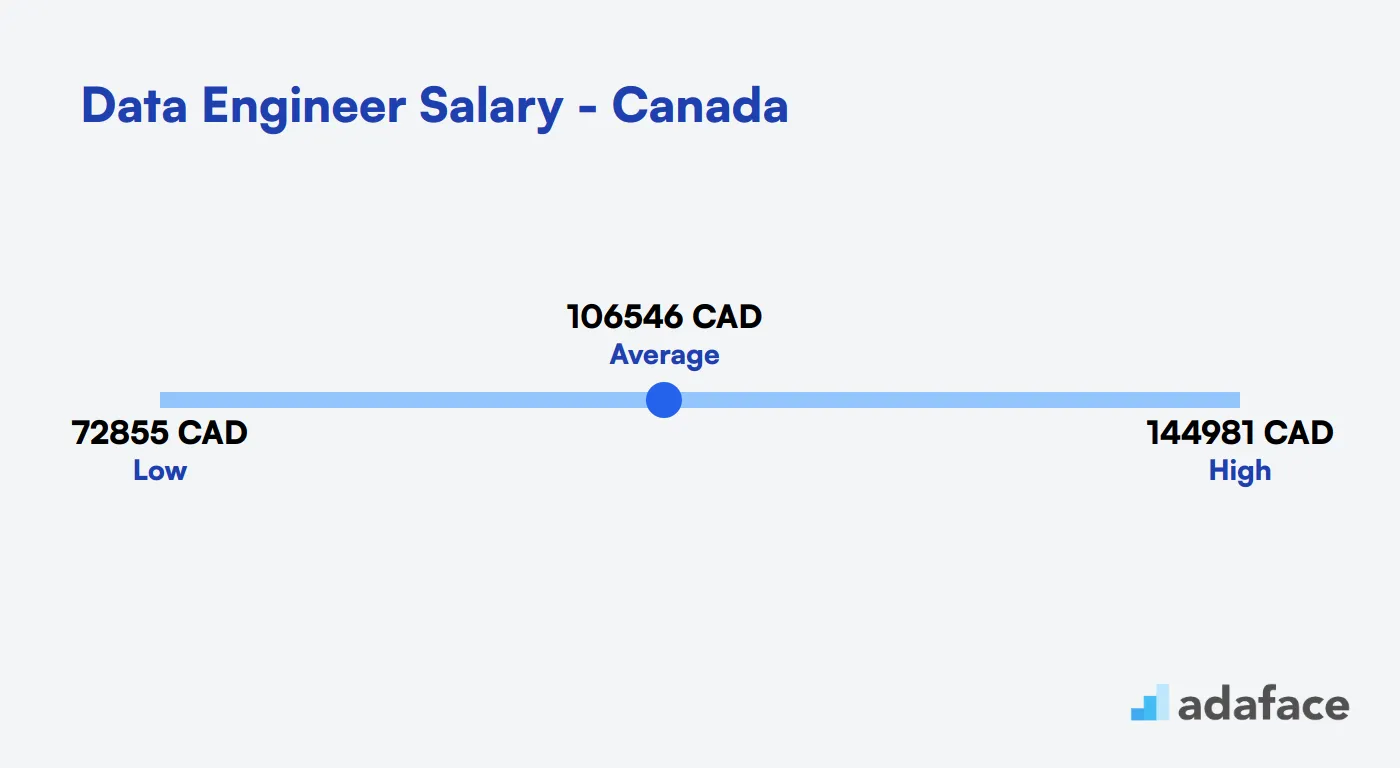
Data Engineer Salary in Canada
In Canada, the average salary for a Data Engineer is approximately 106,546 CAD annually, with a range from 72,856 CAD to 144,981 CAD. Salaries can vary significantly based on location. For instance, Data Engineers in the Greater Toronto Area have an average salary of about 161,147 CAD, whereas in Ottawa, it is around 98,140 CAD. These figures indicate the dynamic nature of compensation across different regions.
What's the difference between a Data Engineer and a Big Data Engineer?
Although the roles of Data Engineer and Big Data Engineer may seem similar, they cater to different scales and complexities of data management. The confusion often arises because both positions involve data infrastructure, but the scope and technologies they work with significantly differ.
A Data Engineer typically focuses on general data infrastructure and pipelines that handle small to medium-sized datasets. They utilize technologies like SQL, ETL tools, and Python, and their work is primarily centered around batch processing and some real-time data management. Team sizes are often smaller, allowing for a more versatile role but with moderate scalability concerns.
On the other hand, a Big Data Engineer is specialized in dealing with large-scale distributed systems. They work with massive datasets, often in the petabyte range, and utilize technologies such as Hadoop, Spark, and NoSQL databases. Their role often necessitates real-time and streaming data processing, with critical performance optimization and a larger, specialized team structure.
| Data Engineer | Big Data Engineer | |
|---|---|---|
| Primary Focus | General data infrastructure and pipelines | Large-scale distributed systems |
| Data Volume | Small to medium-sized datasets | Massive datasets (petabytes) |
| Technologies | SQL, ETL tools, Python | Hadoop, Spark, NoSQL databases |
| Scalability Concerns | Moderate | Critical |
| Cloud Expertise | Beneficial | Essential |
| Data Processing | Batch and some real-time | Primarily real-time and streaming |
| Performance Optimization | Important | Crucial |
| Team Size | Often smaller teams | Usually larger, specialized teams |
What are the ranks of Data Engineers?
The data engineering field is often misunderstood, with roles sometimes overlapping and varying significantly from one organization to another. Understanding the different ranks can help clarify expectations and responsibilities.
• Junior Data Engineer: This is an entry-level position where individuals are typically just starting their careers in data engineering. They focus on learning the tools and techniques required to manage and process data, often working under the guidance of more experienced engineers.
• Data Engineer: At this level, engineers are expected to have a solid understanding of data architecture and data storage solutions. They design, build, and maintain the systems that allow organizations to work with large datasets effectively.
• Senior Data Engineer: Senior Data Engineers have a wealth of experience and are responsible for overseeing complex data projects. They mentor junior engineers and make high-level decisions regarding data strategies and technologies to be employed.
• Lead Data Engineer: This role involves leading a team of data engineers and coordinating projects. A Lead Data Engineer not only designs data pipelines but also collaborates closely with other departments to align data initiatives with business goals.
• Data Engineering Manager: At the management level, this position requires a blend of technical and leadership skills. A Data Engineering Manager oversees the engineering team and ensures that data systems align with the company's objectives and deliver value across the organization.
Hire the Best Data Engineers for Your Team
Throughout this guide, we've explored the role of Data Engineers, their key skills, and effective hiring strategies. From crafting compelling job descriptions to conducting technical interviews, each step plays a role in finding the right talent for your data team.
If there's one key takeaway, it's the importance of using accurate job descriptions and skills tests to make your hiring process more precise. By focusing on these elements, you'll be better equipped to identify and attract top Data Engineering talent that aligns with your organization's specific needs.
Data Engineer Test
45 mins | 13 MCQs and 1 Coding Question
The Data Engineer Online Test uses scenario-based multiple-choice questions to evaluate candidates on their expertise in data engineering, which involves designing, building, and maintaining data architectures, databases, and processing systems. The test gauges candidates' proficiency in data modeling and warehousing, ETL (Extract, Transform, Load) processes, data pipeline construction, distributed computing systems, database systems, data security principles, and performance optimization strategies for data systems.
Try Data Engineer Test
FAQs
What are the most important skills to look for in a data engineer?
Key skills for data engineers include proficiency in SQL, Python, big data technologies (like Hadoop and Spark), cloud platforms, data modeling, and ETL processes. Strong problem-solving abilities and communication skills are also crucial.
How can I assess a data engineer's technical skills during the hiring process?
Use a combination of coding tests, technical interviews, and practical assignments. Our data engineer assessment test can help you evaluate candidates' skills objectively.
What's the difference between a data engineer and a data scientist?
Data engineers focus on building and maintaining data infrastructure, while data scientists analyze data to derive insights. Data engineers prepare the data that data scientists use for analysis.
Where are the best places to find qualified data engineer candidates?
Look for candidates on specialized job boards, LinkedIn, GitHub, and at tech conferences. Employee referrals and partnerships with universities can also be effective sources.
How long does it typically take to hire a data engineer?
The hiring process for a data engineer can take anywhere from 4 to 8 weeks, depending on your company's recruitment process and the availability of qualified candidates.
What should I include in a data engineer job description to attract top talent?
Include specific technical requirements, details about your data stack, interesting projects they'll work on, and growth opportunities. Our data engineer job description template can help you craft an attractive posting.
How can I ensure a good cultural fit when hiring a data engineer?
Include team members in the interview process, ask behavioral questions, and consider a trial project or pair programming session to see how the candidate collaborates with your team.
40 min skill tests.
No trick questions.
Accurate shortlisting.
We make it easy for you to find the best candidates in your pipeline with a 40 min skills test.
Try for freeRelated posts
Free resources

Join 1200+ companies in 80+ countries.
Try the most candidate friendly skills assessment tool today.

40 min tests.
No trick questions.
Accurate shortlisting.
No trick questions.
Accurate shortlisting.