
Linear Regression: Linear regression is a statistical modeling technique that aims to establish a linear relationship between the dependent variable and one or more independent variables. It is measured in this test to assess the candidate's understanding of basic regression concepts and their ability to apply linear regression models in solving real-world problems.
Gradient Descent: Gradient descent is an optimization algorithm widely used in machine learning to minimize the cost function of a model. It iteratively adjusts the model's parameters in the direction of steepest descent to find the optimal solution. Measuring this skill helps evaluate a candidate's proficiency in implementing and optimizing machine learning models through gradient-based methods.
Overfitting and Underfitting: Overfitting occurs when a machine learning model fits the training data too closely, leading to poor generalization and performance on unseen data. Underfitting, on the other hand, happens when the model is too simple and fails to capture the underlying patterns in the data. Assessing a candidate's understanding of overfitting and underfitting helps gauge their knowledge in model complexity and their ability to find the right balance for optimal performance.
Support Vector Machines: Support Vector Machines (SVM) are supervised learning algorithms used for classification and regression tasks. They find an optimal hyperplane that separates different classes or predicts continuous values. Measurement of this skill helps recruiters evaluate the candidate's competence in utilizing SVMs and their ability to handle both linear and non-linear classification or regression problems.
Bias and Variance: Bias refers to the error introduced by a model's overly simplistic assumptions, while variance measures the model's sensitivity to fluctuations in the training data. These two concepts help in understanding the trade-off between underfitting and overfitting. Evaluating a candidate's knowledge of bias and variance enables recruiters to assess their understanding of model performance and the ability to fine-tune models for better results.
Cross-Validation: Cross-validation is a technique used to assess the performance and generalization capabilities of machine learning models. It involves splitting the data into multiple subsets for training and testing, enabling a more robust evaluation of a model's performance. Evaluating a candidate's knowledge of cross-validation helps determine their expertise in model evaluation and their ability to avoid over-optimistic performance estimates.
Supervised Learning: Supervised learning is a machine learning task where a model learns from labeled data to make predictions or classifications. It involves having a clear target variable that the model aims to predict. Assessing this skill helps gauge a candidate's understanding of supervised learning algorithms and their ability to apply them to various prediction tasks.
Unsupervised Learning: Unsupervised learning is a machine learning task where a model learns from unlabeled data to find patterns or structures without specific target variables. This skill measures a candidate's familiarity with unsupervised learning algorithms, such as clustering and dimensionality reduction, and their ability to extract meaningful insights from unstructured data.
Clustering: Clustering is an unsupervised learning technique that groups similar data points together based on their characteristics or similarities. It helps identify natural structures or categories within data. Evaluating a candidate's knowledge of clustering algorithms signifies their proficiency in exploring patterns within data and their ability to segment datasets into meaningful clusters for further analysis.
Dimensionality Reduction: Dimensionality reduction is the process of reducing the number of input variables/features in machine learning models. It helps simplify complex datasets by removing redundant or irrelevant features while retaining essential information. Assessing this skill allows recruiters to evaluate a candidate's understanding of feature selection techniques and their ability to improve model performance and interpretability.
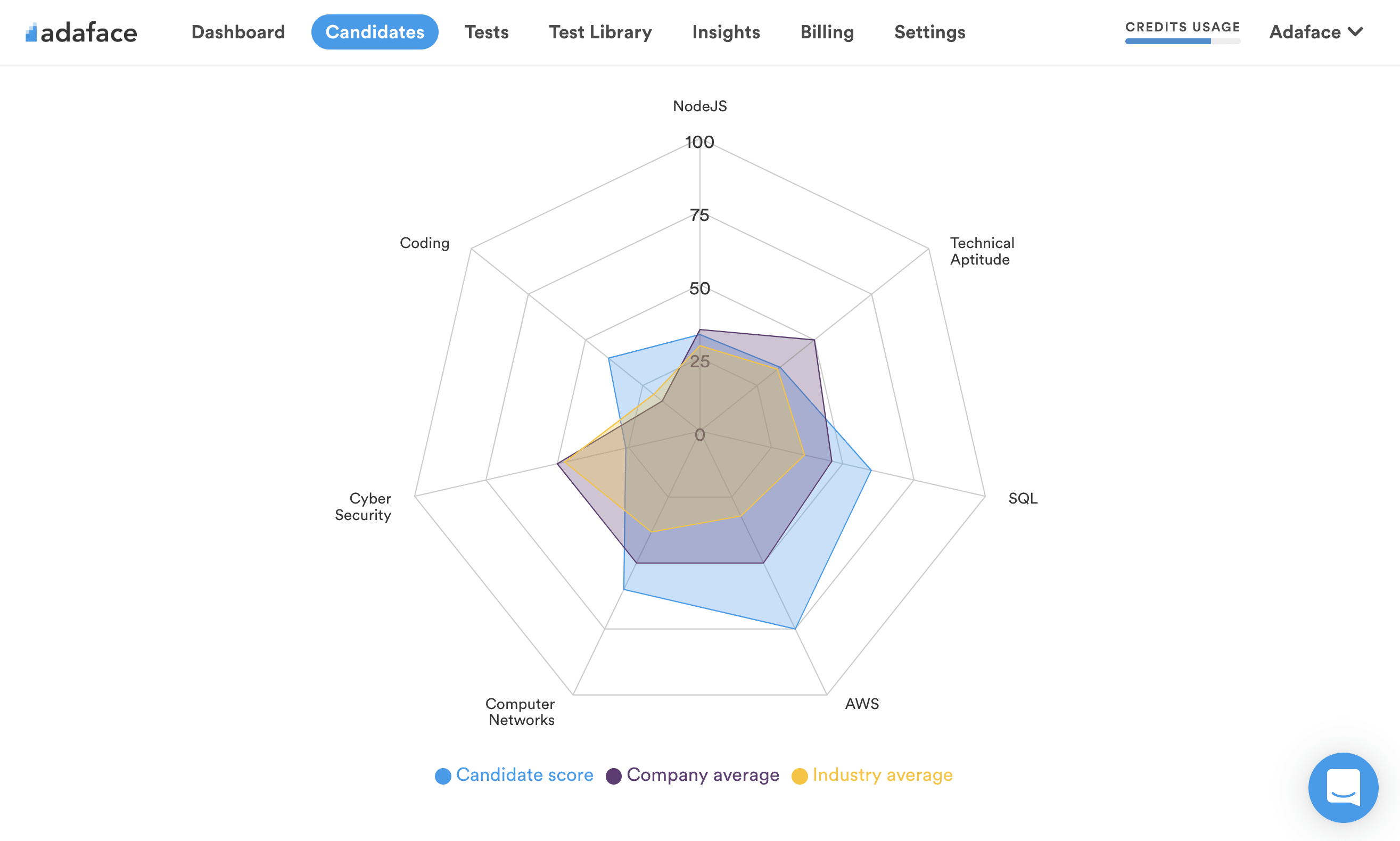
Model Evaluation: Model evaluation is the process of assessing the performance and quality of machine learning models. It involves using various metrics and techniques to measure how well a model generalizes to unseen data. Evaluating this skill helps recruiters determine a candidate's proficiency in evaluating and comparing different models and their ability to select the most appropriate one for a given task.
Feature Engineering: Feature engineering is the process of creating new features or transforming existing ones to improve the performance of machine learning models. It involves selecting, creating, or modifying variables to better represent the underlying patterns in the data. Measuring this skill enables recruiters to assess a candidate's expertise in enhancing the predictive power of models through insightful feature engineering techniques.