Medium Multi Select | Solve |
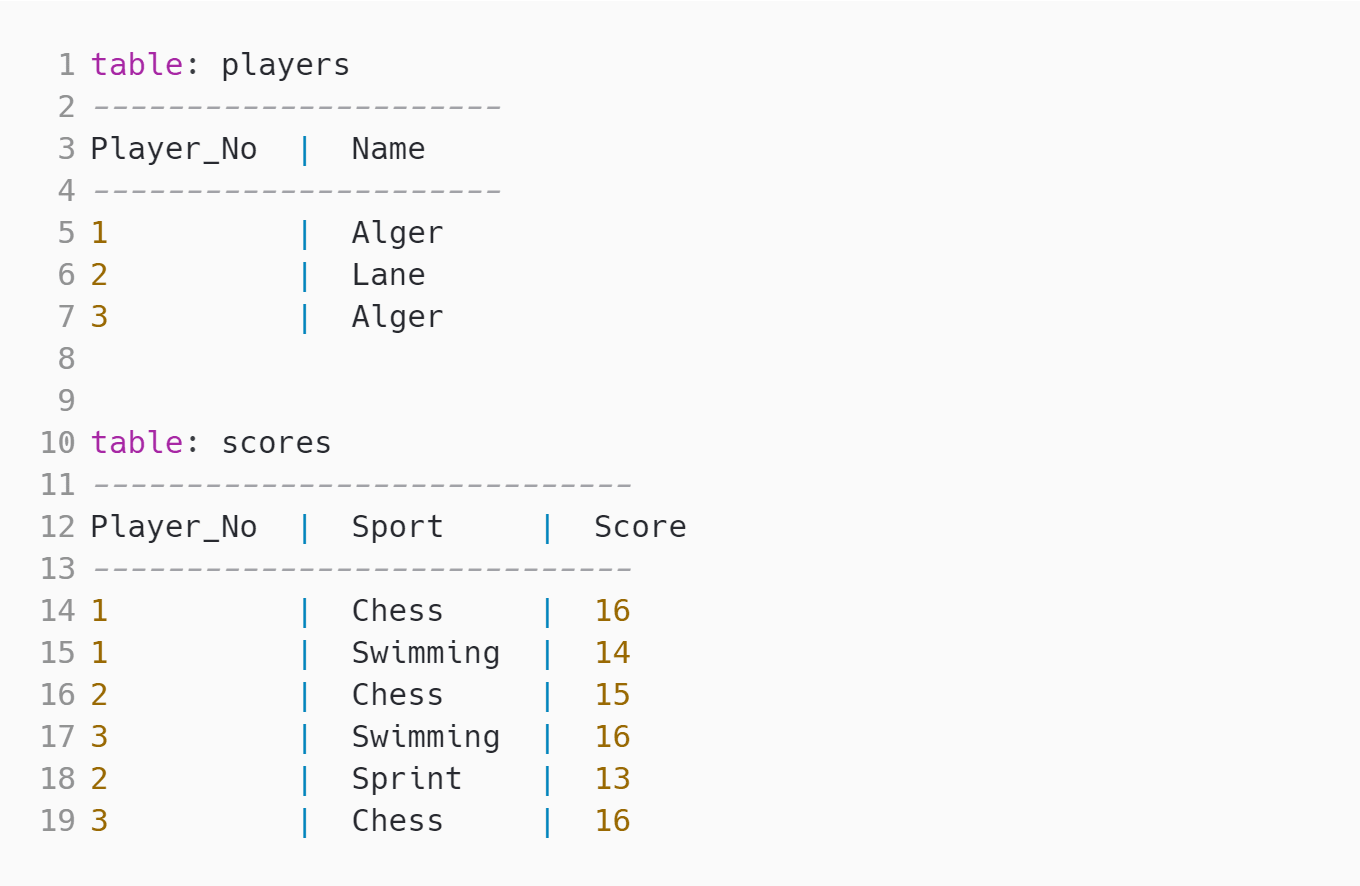
Consider the following SQL table:
How many rows does the following SQL query return?
|
Medium nth highest sales | Solve |
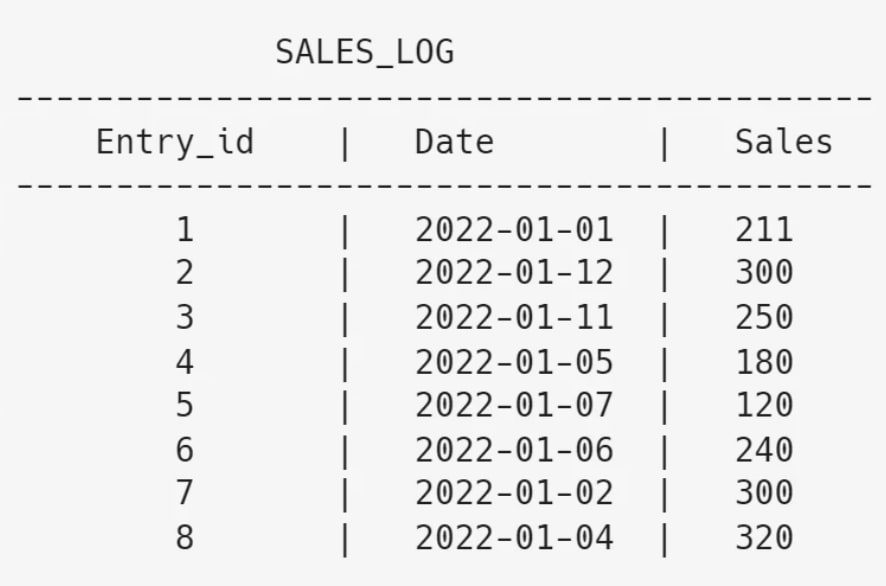
Consider the following SQL table:
Which of the following SQL commands will find the ‘nth highest Sales’ if it exists (returns null otherwise)?
|
Medium Select & IN | Solve |
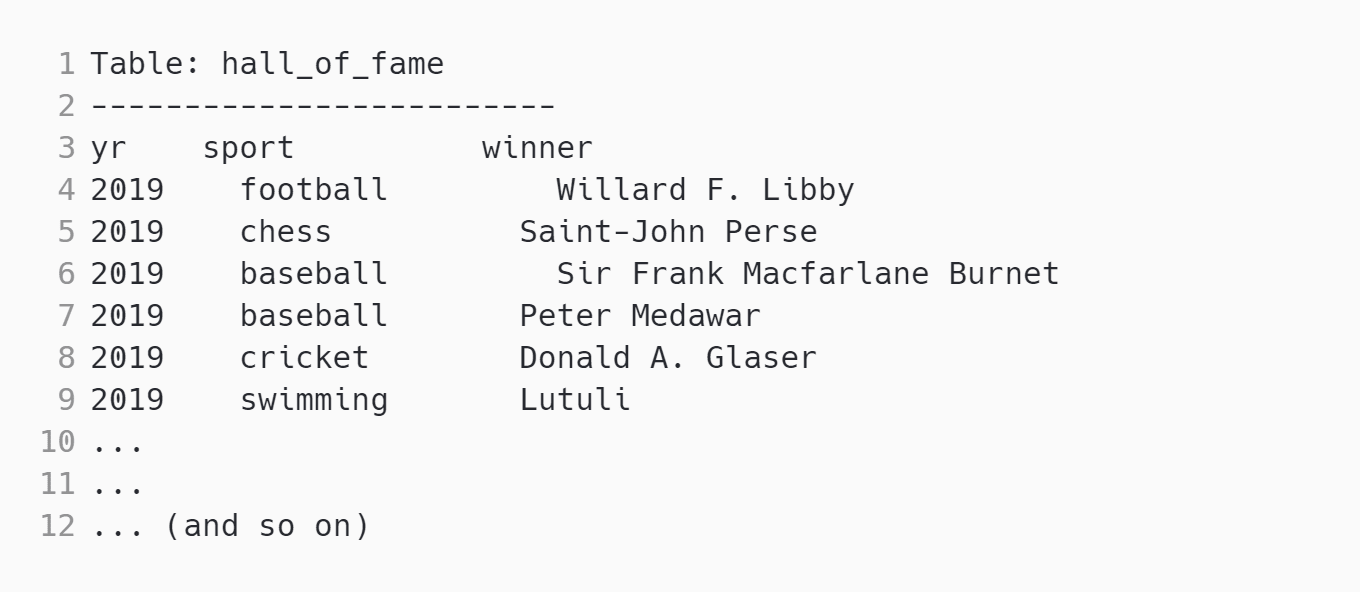
Consider the following SQL table:
Which of the following SQL queries would return the year when neither a football or cricket winner was chosen?
|
Medium Sorting Ubers | Solve |
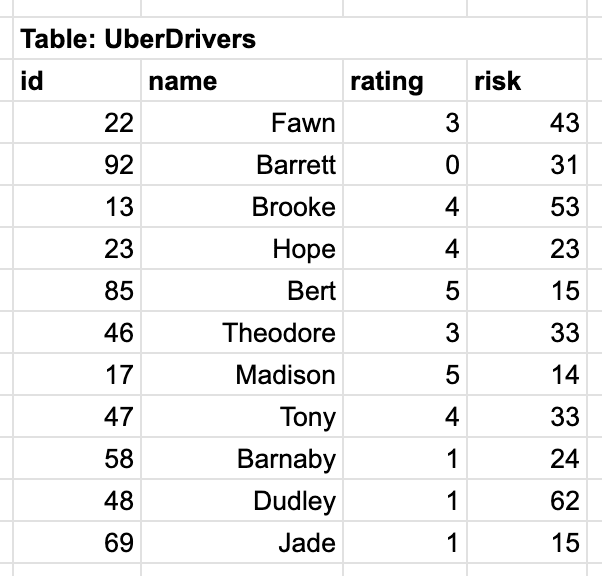
Consider the following SQL table:
What will be the first two tuples resulting from the following SQL command?
|
Hard With, AVG & SUM | Solve |
Consider the following SQL table:
How many tuples does the following query return?
|
Medium Marketing Database | Solve |
You are a data warehouse engineer at a marketing agency, managing a large-scale database that stores extensive data on customer interactions, campaign metrics, and market research. The database is used predominantly for complex analytical queries, such as segment analysis, trend identification, and campaign performance evaluation. These queries often involve aggregations, filtering, and joining over large datasets.
The existing setup, using traditional row-oriented storage, is struggling with performance issues, particularly for ad-hoc analytical queries that span multiple tables and require aggregating large volumes of data.
The main tables in the database are:
- Customer_Interactions (millions of rows): Stores individual customer interaction data.
- Campaign_Metrics (hundreds of thousands of rows): Contains detailed metrics for each marketing campaign.
- Market_Research (tens of thousands of rows): Holds market research data and findings.
Considering the nature of the queries and the structure of the data, which of the following changes would most effectively optimize the query performance for analytical purposes?
A: Normalize the database further by splitting large tables into smaller, more focused tables and creating indexes on frequently joined columns.
B: Implement an in-memory database system to facilitate faster data retrieval and processing.
C: Convert the database to use columnar storage, optimizing for the types of analytical queries performed in the marketing context.
D: Create a series of materialized views to pre-aggregate data for common query patterns.
E: Increase the hardware capacity of the server, focusing on faster CPUs and more RAM.
F: Implement partitioning on the main tables based on commonly filtered attributes, such as campaign IDs or time periods.
|
Medium Multidimensional Data Modeling | Solve |
As a senior data warehouse engineer at a large retail company, you are tasked with designing a multidimensional data model to support complex OLAP (Online Analytical Processing) operations for retail analytics. The company operates in multiple countries and deals with a wide range of products. The primary requirement is to enable efficient analysis of sales performance across various dimensions such as time, geography, product categories, and sales channels.
The source data resides in a transactional system with the following tables:
- Transactions (Transaction_ID, Date, Store_ID, Product_ID, Quantity, Unit_Price)
- Stores (Store_ID, Store_Name, Country, Region)
- Products (Product_ID, Product_Name, Category, Supplier_ID)
- Suppliers (Supplier_ID, Supplier_Name, Country)
You need to design a schema in the data warehouse that facilitates fast querying for aggregations and comparisons along the mentioned dimensions. Which of the following schemas would best serve this purpose?
A: A star schema with a central fact table linking to dimension tables for Time, Store, Product, and Supplier.
B: A snowflake schema where dimension tables for Store, Product, and Supplier are normalized.
C: A galaxy schema with separate fact tables for Transactions, Inventory, and Supplier Orders, linked to shared dimension tables.
D: A flat schema combining all source tables into a single wide table to avoid joins during querying.
E: An OLTP-like normalized schema to maintain data integrity and minimize redundancy.
F: A hybrid schema using a star schema for frequently queried dimensions and a snowflake schema for less queried, more detailed dimensions.
|
Medium Optimizing Query Performance | Solve |
As a senior data warehouse developer, you are tasked with optimizing query performance in a large-scale data warehouse that primarily stores transactional data for a global retail company. The data warehouse is facing significant performance issues, particularly with certain types of queries that are crucial for business operations. After analysis, you identify that the most problematic queries are those that involve filtering and aggregating transaction data based on time periods (e.g., monthly sales) and specific product categories.
The main transaction table (Transactions) in the data warehouse has the following structure and characteristics:
- Columns: Transaction_ID (bigint), Transaction_Date (date), Product_ID (int), Quantity (int), Price (decimal), Category_ID (int)
- Row count: Approximately 2 billion rows
- Most common query pattern: Aggregating Quantity and Price by Category_ID and Transaction_Date (e.g., total sales per category per month)
- Current indexing: Primary key index on Transaction_ID, no other indexes
Based on this information, which of the following approaches would most effectively optimize the query performance for the given use case?
A: Add a non-clustered index on Transaction_Date and Category_ID.
B: Normalize the Transactions table by splitting Transaction_Date and Category_ID into separate dimension tables.
C: Implement partitioning on the Transactions table by Transaction_Date, and add a bitmap index on Category_ID.
D: Convert the Transactions table to use a columnar storage format.
E: Create a materialized view that pre-aggregates data by Category_ID and Transaction_Date.
F: Increase the hardware capacity of the data warehouse server, focusing on CPU and memory upgrades.
|
Medium Data Merging | Solve |
A data engineer is tasked with merging and transforming data from two sources for a business analytics report. Source 1 is a SQL database 'Employee' with fields EmployeeID (int), Name (varchar), DepartmentID (int), and JoinDate (date). Source 2 is a CSV file 'Department' with fields DepartmentID (int), DepartmentName (varchar), and Budget (float). The objective is to create a summary table that lists EmployeeID, Name, DepartmentName, and YearsInCompany. The YearsInCompany should be calculated based on the JoinDate and the current date, rounded down to the nearest whole number. Consider the following initial SQL query:
Which of the following modifications ensures accurate data transformation as per the requirements?
A: Change FLOOR to CEILING in the calculation of YearsInCompany.
B: Add WHERE e.JoinDate IS NOT NULL before the JOIN clause.
C: Replace JOIN with LEFT JOIN and use COALESCE(d.DepartmentName, 'Unknown').
D: Change the YearsInCompany calculation to YEAR(CURRENT_DATE) - YEAR(e.JoinDate).
E: Use DATEDIFF(YEAR, e.JoinDate, CURRENT_DATE) for YearsInCompany calculation.
|
Medium Data Updates | Solve |
Jaylo is hired as Data warehouse engineer at Affflex Inc. Jaylo is tasked with designing an ETL process for loading data from SQL server database into a large fact table. Here are the specifications of the system:
1. Orders data from SQL to be stored in fact table in the warehouse each day with prior day’s order data
2. Loading new data must take as less time as possible
3. Remove data that is more then 2 years old
4. Ensure the data loads correctly
5. Minimize record locking and impact on transaction log
Which of the following should be part of Jaylo’s ETL design?
A: Partition the destination fact table by date
B: Partition the destination fact table by customer
C: Insert new data directly into fact table
D: Delete old data directly from fact table
E: Use partition switching and staging table to load new data
F: Use partition switching and staging table to remove old data
|
Medium SQL in ETL Process | Solve |
In an ETL process designed for a retail company, a complex SQL transformation is applied to the 'Sales' table. The 'Sales' table has fields SaleID, ProductID, Quantity, SaleDate, and Price. The goal is to generate a report that shows the total sales amount and average sale amount per product, aggregated monthly. The following SQL code snippet is used in the transformation step:
What specific function does this SQL code perform in the context of the ETL process, and how does it contribute to the reporting goal?
A: The code calculates the total and average sales amount for each product annually.
B: It aggregates sales data by month and product, computing total and average sales amounts.
C: This query generates a daily breakdown of sales, both total and average, for each product.
D: The code is designed to identify the best-selling products on a monthly basis by sales amount.
E: It calculates the overall sales and average price per product, without considering the time dimension.
|
Medium Trade Index | Solve |
Silverman Sachs is a trading firm and deals with daily trade data for various stocks. They have the following fact table in their data warehouse:
Table: Trades
Indexes: None
Columns: TradeID, TradeDate, Open, Close, High, Low, Volume
Here are three common queries that are run on the data:
Dhavid Polomon is hired as an ETL Developer and is tasked with implementing an indexing strategy for the Trades fact table. Here are the specifications of the indexing strategy:
- All three common queries must use a columnstore index
- Minimize number of indexes
- Minimize size of indexes
Which of the following strategies should Dhavid pick:
A: Create three columnstore indexes:
1. Containing TradeDate and Close
2. Containing TradeDate, High and Low
3. Container TradeDate and Volume
B: Create two columnstore indexes:
1. Containing TradeID, TradeDate, Volume and Close
2. Containing TradeID, TradeDate, High and Low
C: Create one columnstore index that contains TradeDate, Close, High, Low and Volume
D: Create one columnstore index that contains TradeID, Close, High, Low, Volume and Trade Date
|